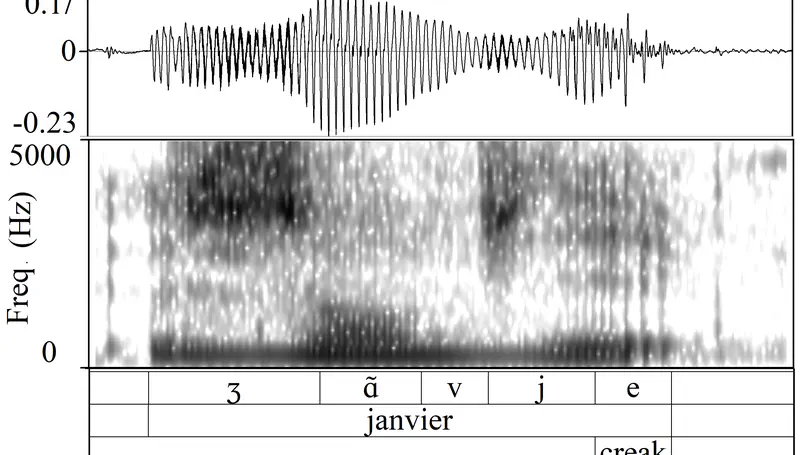
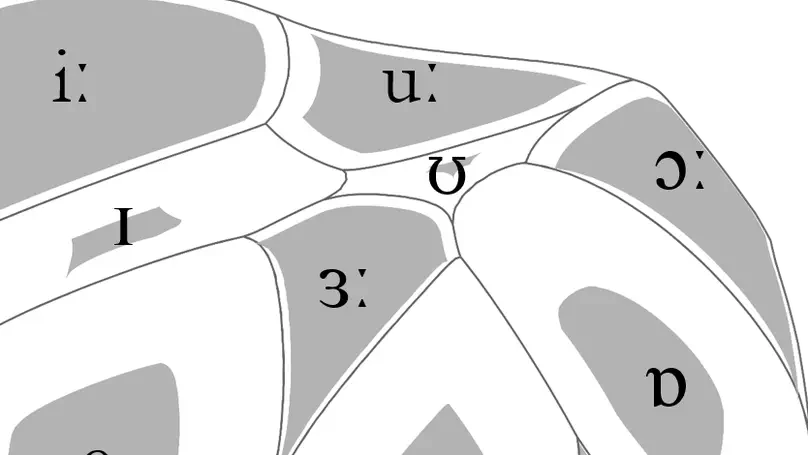
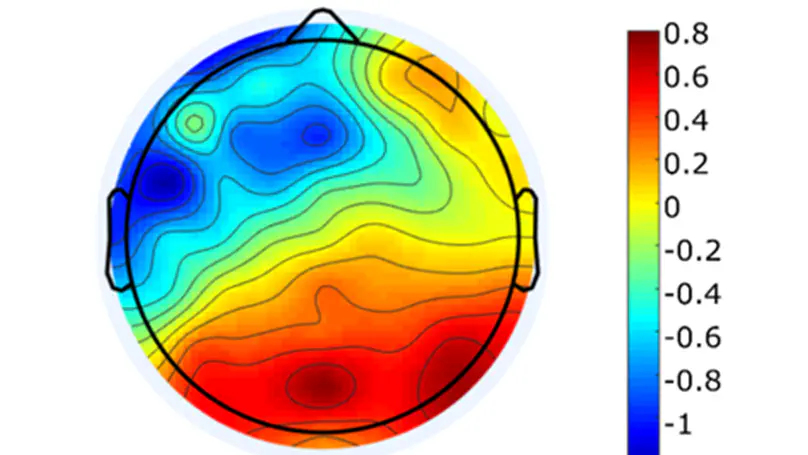
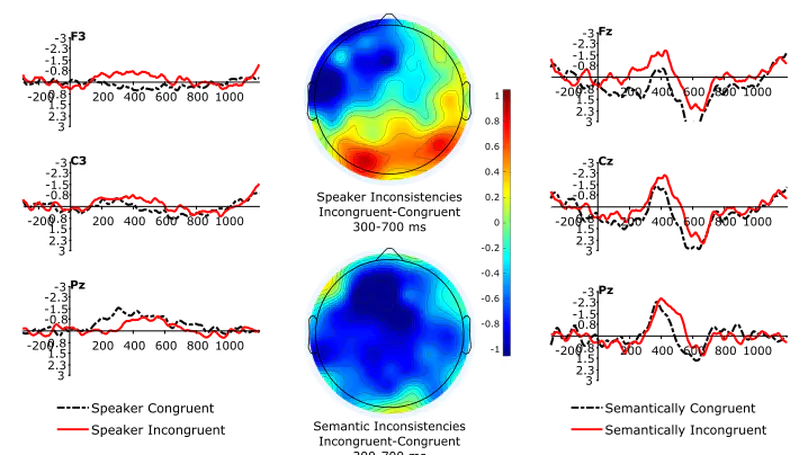
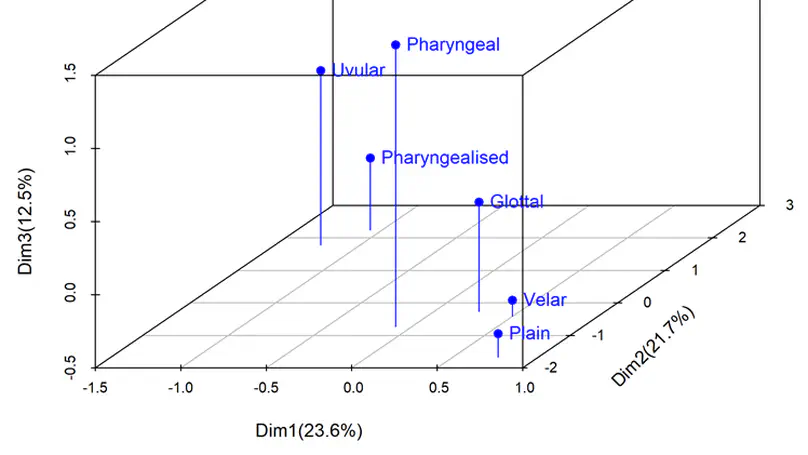
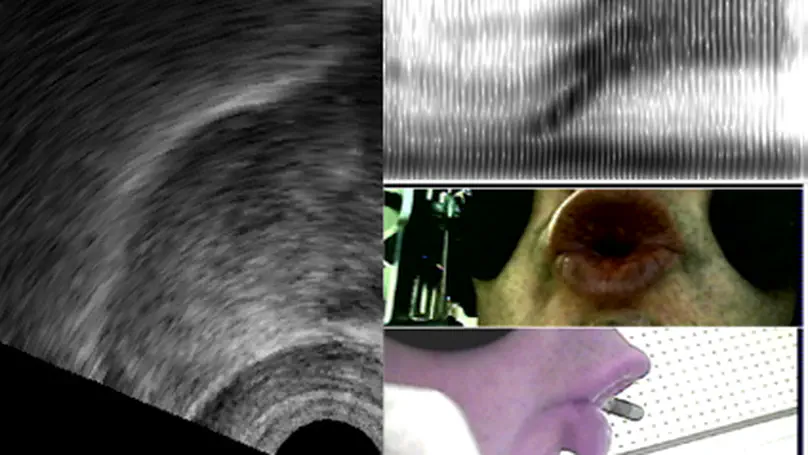
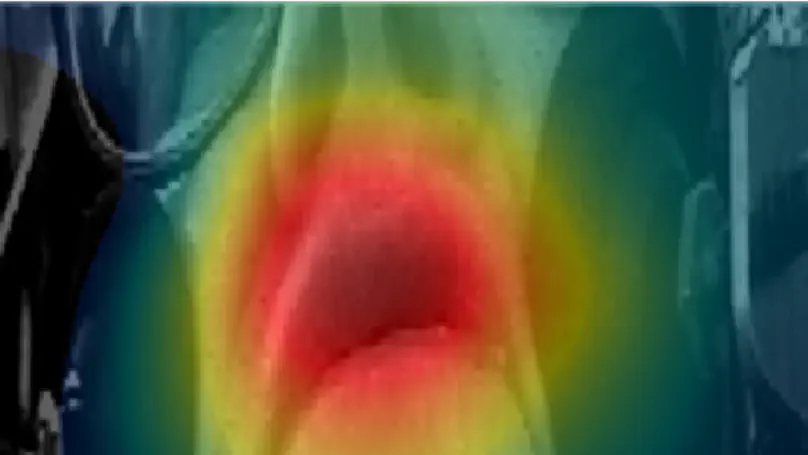
Modern phonetics has relied, to a large extent, on researchers’ ability to extract patterns from visual representations of speech. In this respect, if linguists were medical doctors, phoneticians would be radiologists. Speaking of radiologists, recent progress in artificial intelligence has made it possible for certain deep learning algorithms to outperform human pathologists at detecting abnormalities in medical images (Litjens et al., 2017). If the analogy holds, it is fair to ask whether artificial intelligence can beat phoneticians at their own game or, at least, constitute a significant addition to their toolbox. My contention is that the advent of deep learning opens up a whole new research programme for the humanities in general, and phonetics in particular. While deep neural networks (DNNs) have been duly praised for bringing about a major breakthrough in applied fields like automatic speech (Hinton et al., 2012) or image (Simonyan & Zisserman, 2015) recognition, we are only just starting to realize how fundamental research in our field can benefit from them (Ferragne et al., 2019; Pellegrini & Mouysset, 2016). There are at least three reasons why DNNs will trigger a paradigm shift in phonetics. Firstly, unlike other quantitative techniques, DNNs can extract relevant representations from the speech signal without the need for a human expert to provide the system with hand-picked features (Goodfellow et al., 2016, for a comprehensive account of DNN properties). As a result, typical workflows now boast improved reproducibility; the possibility is raised that previously unnoticed parameters can be brought to light; and manual segmentation – a major bottleneck in phonetic analysis – is no longer needed in some cases. Secondly, deep learning will contribute to bringing the old parsimony-driven paradigm to a close. There is a whole record of experimental research that demonstrates that mental phonetic representations are detailed and multidimensional (Pierrehumbert, 2016). So, now that the high-dimensionality taboo has been broken, and that increasingly powerful and cheap computing resources have become available, the time is just right for the emergence of DNNs in phonetics, with their rich inputs and outputs. Thirdly, the current focus on explicability in the deep learning community has led to effective methods to visualize what DNNs learn (Chattopadhay et al., 2018). My claim here is that scientific findings based on visuals are key to bridging the divide between the hard sciences and humanities. And “visible speech”, the powerful synaesthetic cornerstone of contemporary phonetics, is more than ever legitimatized by DNN-based methods. Moreover, such techniques undoubtedly represent the logical alternative to the modern unreasonable urge to (over-) use inferential statistics and its misleading probability values. I will illustrate these claims with examples taken from on-going work in this nascent research field. I will more specifically focus on how convolutional neural networks used in image recognition and computer vision can be adapted to the study of phonetics. I will discuss the advantages and shortcomings of this novel approach, and I hope to show that while deep learning lies at the intersection of experimental and corpus phonetics, it offers the best of both worlds.



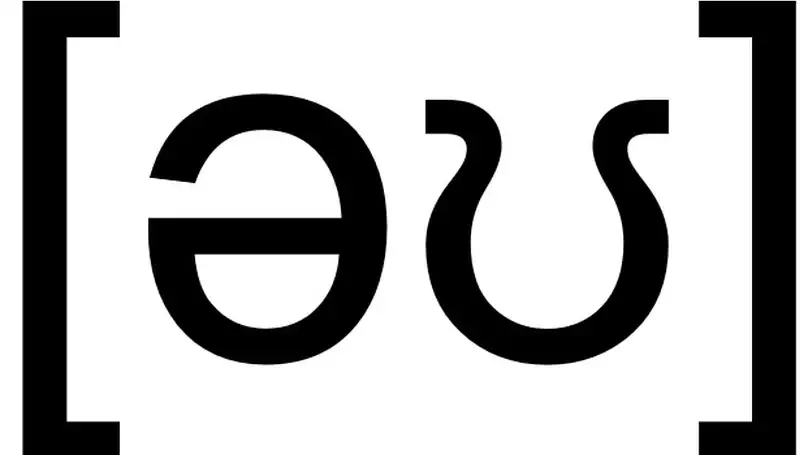

![[ɹ], [w] or [ʁ]: Investigating French advanced learners' productions of English /r/](/talk/%C9%B9-w-or-%CA%81-investigating-french-advanced-learners-productions-of-english-/r/featured_huf04e41ab7ab5b8c501a055280a804cf2_38383_808x455_fill_q75_h2_lanczos_smart1.webp)









![Me[t]al or Me[ɾ]al? The Role of Duration and Lexical Frequency on /t/ Flapping in the Singing Voice](/talk/metal-or-me%C9%BEal-the-role-of-duration-and-lexical-frequency-on-/t/-flapping-in-the-singing-voice/featured_hu06c6b10bf9d52a2986b5de5bfdaffa80_90388_808x455_fill_q75_h2_lanczos_smart1.webp)