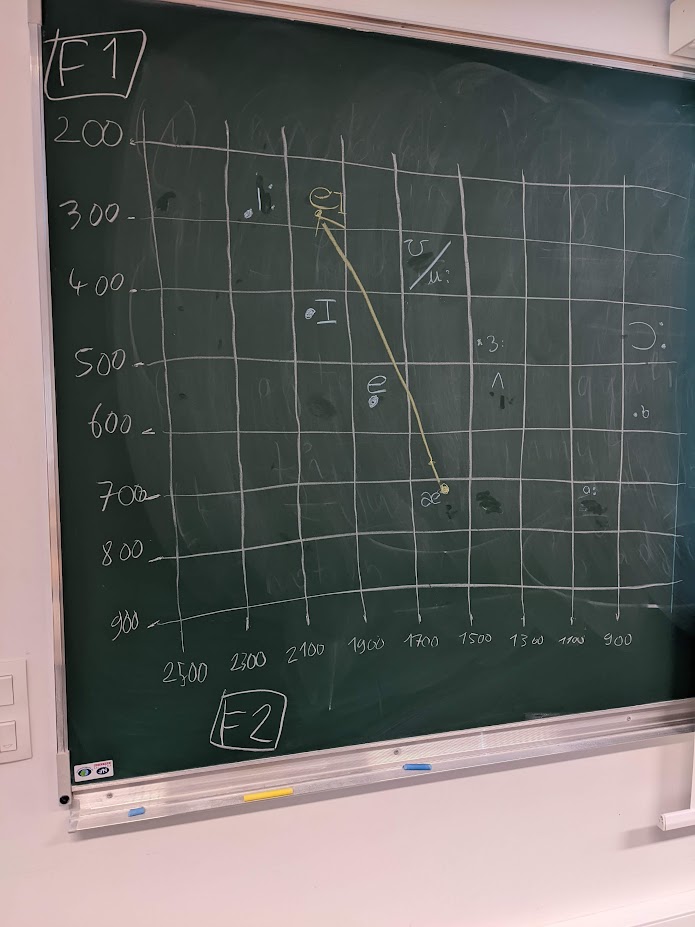Emmanuel Ferragne
Professor of Phonetics
Deputy head of ALTAE
Works at Université Paris Cité
Institut Universitaire de France (IUF)
inIdEx Empirical Foundations of Linguistics (EFL)
About me
I am a full professor of phonetics in the English Studies department at Université Paris Cité.
Interests
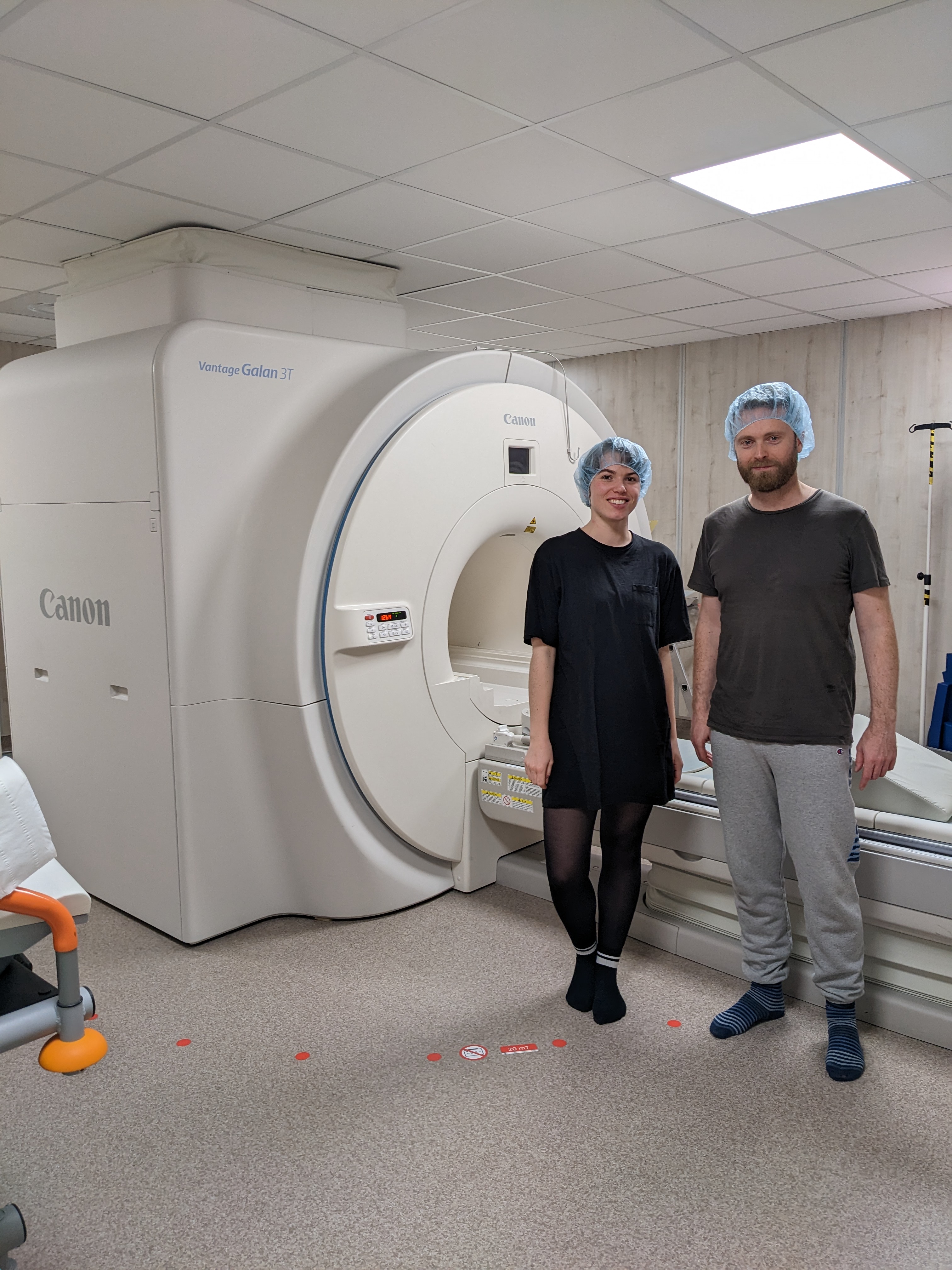
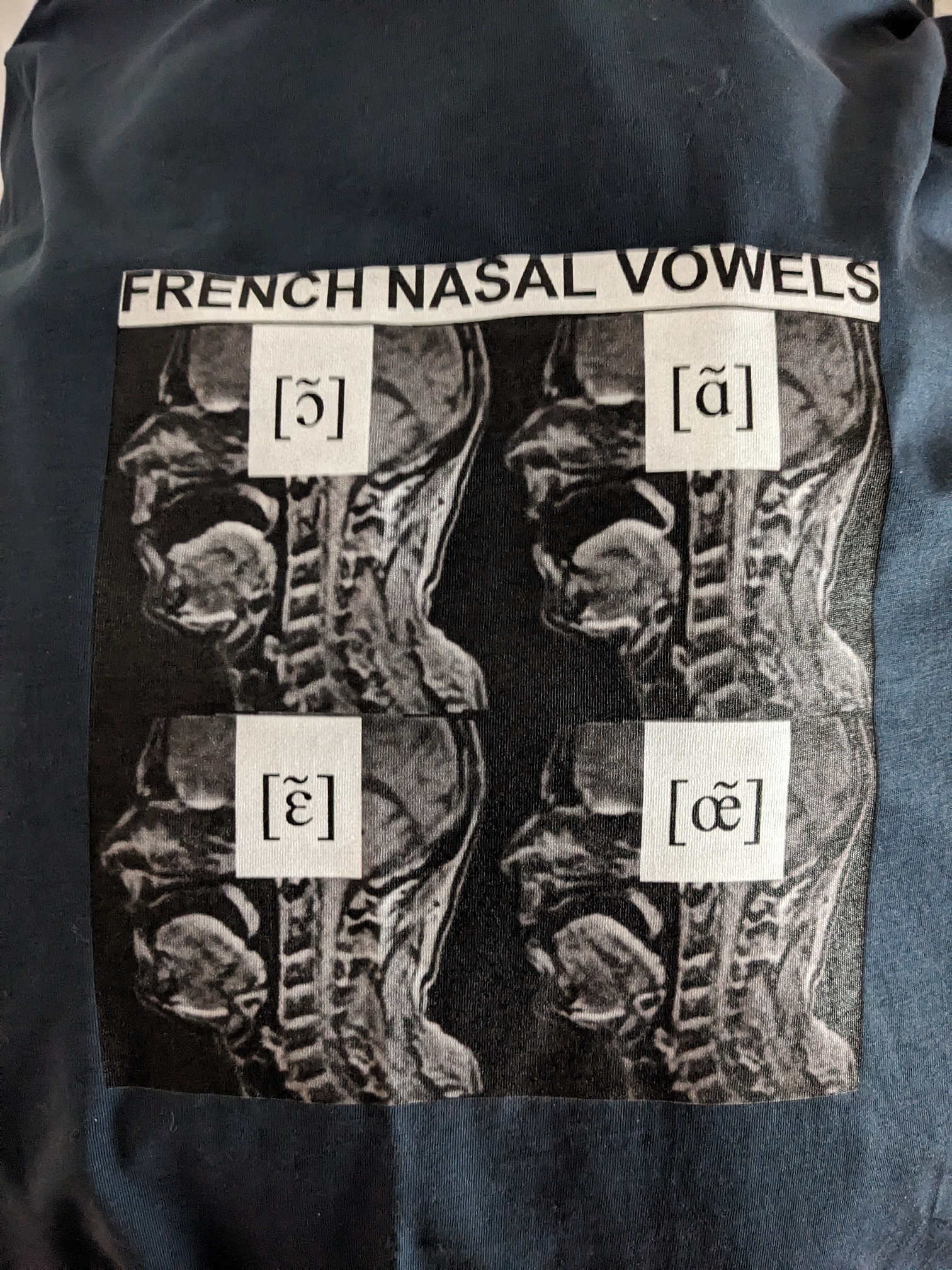
- Sociophonetics/Neurophonetics
- Forensic phonetics
- Learners’ pronunciation
Featured Publications

Recent Publications
Quickly discover relevant content by filtering publications.

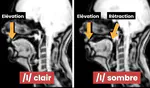


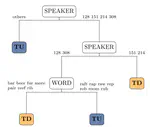

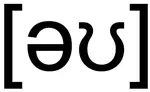

![[ɹ], [w] or [ʁ]: Investigating French advanced learners' productions of English /r/](/talk/%C9%B9-w-or-%CA%81-investigating-french-advanced-learners-productions-of-english-/r/featured_huf04e41ab7ab5b8c501a055280a804cf2_38383_150x0_resize_q75_h2_lanczos.webp)




Projects
*






SARA: Sound Articulations Reinforce Acquisition
Perception de l’Anglais et Reconnaissance Automatique d’Accents à la Fac
Solutions pour l’Enseignement de la Phonétique Appliquée aux Langues Étrangères
VoCSI-Telly: Voice and Crime Scene Investigators on Telly
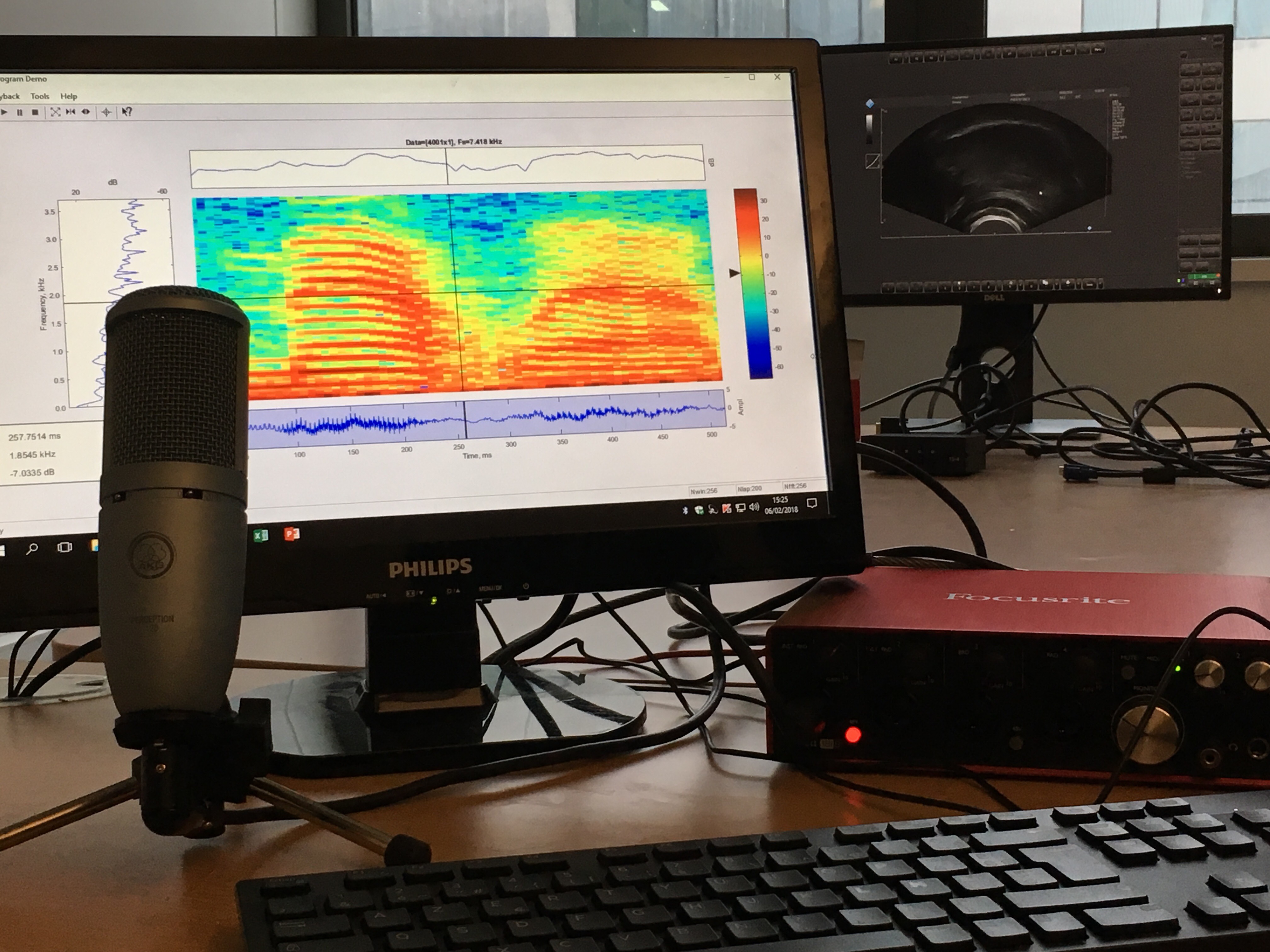
Praat and R code for a doctoral seminar I teach at Université Paris Diderot.Forensic Voice Comparison
A super useful software program to record
speech corpora.Gallery